1. 유니온 파인드
개요
일반적으로 여러 노드가 있을 때 특정 2개의 노드를 연결해 1개의 집합으로 묶는 union 연산과
두 노드가 같은 집합에 속해 있는지를 확인하는 find 연산으로 구성된 알고리즘
union, find 연산을 완벽히 이해하는 것이 핵심
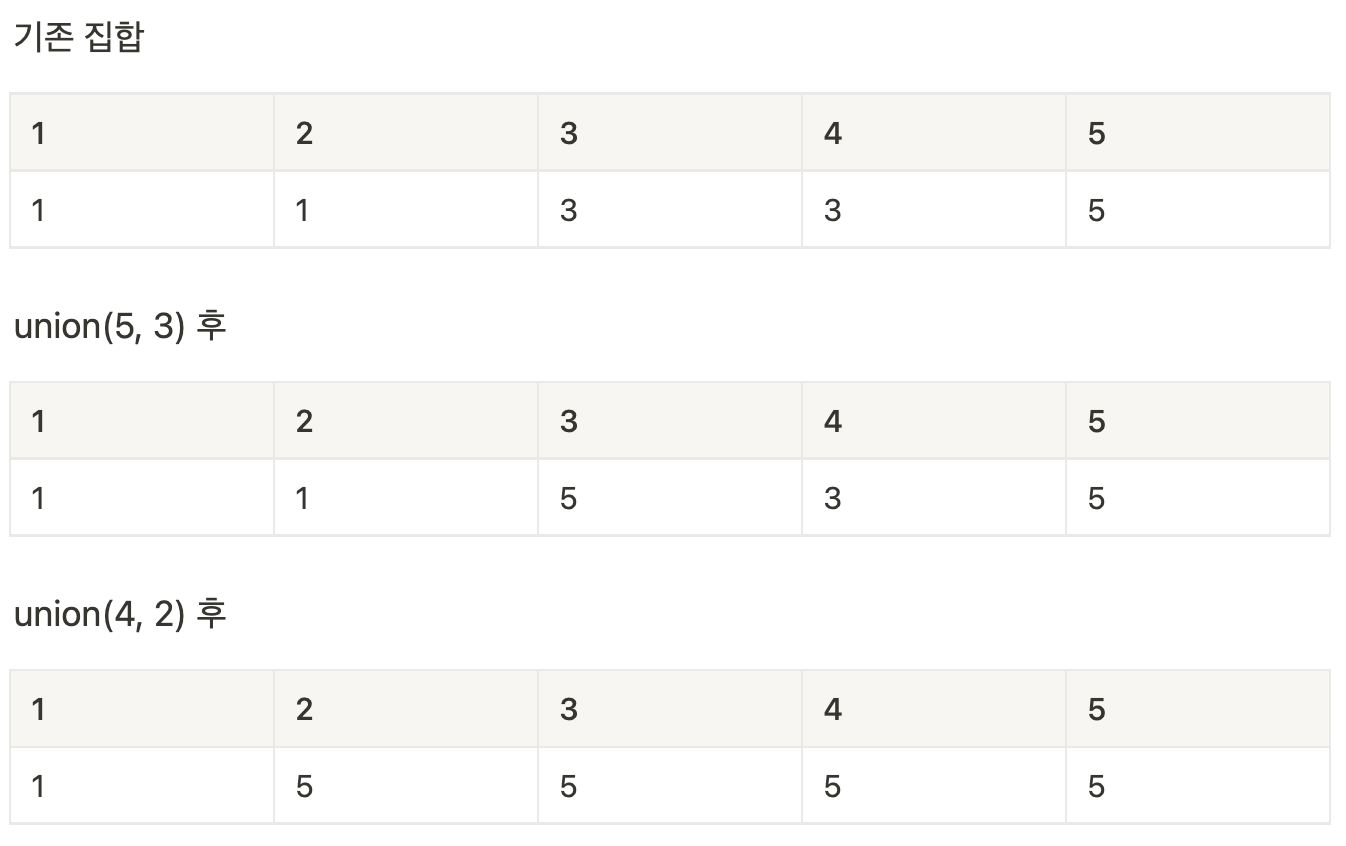
- union 연산: 각 노드가 속한 집합을 1개로 합치는 연산. 노드 a, b가 a { A, b { B일 때 union(a,b)는 A U B를 말함.
- find 연산: 특정 노드 a에 관해 a가 속한 집합의 대표 노드를 반환하는 연산. 노드 a가 a { A 일때 find(a)는 집합의 대표 노드를 반환
구현 방법
1차원 리스트 이용
- 노드가 연결되어 있지 않으므로 각 노드가 대표 노드가 됨. 1차원 리스트를 자신의 인덱스값으로 초기화.
- union 연산
- 각 노드가 속한 집합을 1개로 합치는 연산.
- union(a, b)할 시 a, b 각각의 대표 노드값 find연산으로 찾아, 대표 노드 두개 중 하나의 값으로 변경.
- find 연산
- find역할 외에도 그래프 정돈 및 시간 복잡도 감소.
- 경로 압축 효과: 여러 노드를 거쳐야 하는 경로에서 그래프를 변형해 더 짧은 경로로 갈 수 있도록 함으로써 시간 복잡도를 효과적으로 줄이는 방법.
- 대상 노드 리스트에 index값과 value값이 동일한지 확인.
- 동일하지 않으면 value값이 가리키는 index위치로 이동.
- 이동 위치의 index값과 value값이 같을 때까지 1~2를 반복. 재귀 함수로 구현.
- 대표 노드(index = value)에 도달하면 재귀 함수를 빠져나오면서 거치는 모든 노드값을 대표 노드값으로 변경.
- find역할 외에도 그래프 정돈 및 시간 복잡도 감소.
조심해야 할 것
더보기
- find 연산 구현 시 재귀를 나오면서 대표 노드값으로 설정
- union 연산 구현 시 find 사용하여 대표 노드끼리 연결
2. 최소 신장 트리(minimum spanning tree)
개요
주어진 그래프의 모든 노드를 연결하는 부분 그래프 중,
사용된 에지들의 가중치의 합을 최소로 하는 트리.
특징
- 사이클이 포함되면 가중치의 합이 최소가 될 수 없으므로 사이클을 포함하지 않는다.
- N개의 노드가 있으면 최소 신장 트리를 구성하는 에지의 개수는 항상 N-1개이다.
에지 리스트를 이용해 구현한다.
에지 리스트
에지를 중심으로 그래프를 표현. 에지 정보를 단순하게 [출발 노드, 도착 노드, 가중치]의 형식으로 리스트 안에 집어넣는다.
- 구현하기 매우 쉬움(단순히 리스트에 에지 정보를 넣으면 됨)
- 특정 노드와 관련되어 있는 에지를 탐색하기 어려움.
- 노드 중심 알고리즘에는 잘 사용하지 않음
- 리스트에 출발 노드 도착 노드를 저장하여 에지를 표현. EX) [[1, 2], [2, 3]]
- 가중치가 있다면 나 추가로 가중치를 저장. EX) [[1, 2, 3], [2, 3, 2]]
최소 신장 트리 구현 방법
- 에지 리스트로 그래프를 구현하고 유니온 파인드 리스트 초기화.
- 노드 변수 2개와 가중치 변수로 구성된 리스트 제작.
- 사이클 처리를 위해 노드 당 유니온 파인드 리스트도 함께 초기화.
- 그래프 데이터를 가중치 기준으로 정렬.
- 에지 리스트에 담긴 그래프 데이터를 가중치 기준으로 오름차순 정렬.
- 가중치가 가장 낮은 에지부터 연결 시도.
- 바로 연결하는 것이 아니라 find연산으로 사이클이 유무를 확인.
- 두 노드의 대표 노드가 서로 같다면 사이클이 만들어짐.
- 형성되지 않을 경우에만 union연산을 이용해 두 노드를 연결.
- 바로 연결하는 것이 아니라 find연산으로 사이클이 유무를 확인.
- 전체 노드 개수가 N개이면 연결한 에지의 개수가 N-1이 될때까지 과정 3 반복.
- 총 에지 비용 출력하기.
백준 1197
https://www.acmicpc.net/problem/1197
import sys
input = sys.stdin.readline
sys.setrecursionlimit(10 ** 6)
def union_find(a):
if union_list[a] == a:
return a
else:
union_list[a] = union_find(union_list[a])
return union_list[a]
def union(a, b):
union_list[a] = union_find(b)
union_list[b] = union_list[a]
V, E = list(map(int, input().split()))
edge_list = []
union_list = [i for i in range(V + 1)]
for i in range(E):
edge_data = list(map(int, input().split()))
edge_list.append(edge_data)
edge_list.sort(key=lambda x: x[2])
cnt = 0
edge_len = 0
if V != 1:
for edge_data in edge_list:
a = union_find(edge_data[0])
b = union_find(edge_data[1])
if a != b:
union_list[a] = b
edge_len += edge_data[2]
cnt += 1
if cnt == V - 1:
break
print(edge_len)
'컴퓨터 공학 분야 별 지식 > 개념(파이썬)' 카테고리의 다른 글
| K번째 최단 거리 찾기 파이썬, 백준 1854 파이썬 (1) | 2024.03.11 |
|---|---|
| 최단거리 찾기 1 - 다익스트라 알고리즘 파이썬, 백준 1753번 파이썬 (0) | 2024.03.10 |
| 우선순위 큐(Priority Queue)와 그리디 알고리즘(Greedy) 파이썬, 백준 1715 파이썬 (1) | 2023.10.28 |
| 큐(queue), BFS(너비 우선 탐색), 트리의 지름, 백준 1167 파이썬 (1) | 2023.10.26 |
| 스택(stack), DFS(깊이 우선 탐색), 이분 그래프, 백준 1707 파이썬 (1) | 2023.10.24 |